









¡Es muy interesante!
estoy sorprendida por los resultados del estudio de ADN y espero con ansias saber más acerca de mis familiares y las coincidencias halladas por My Heritage en los árboles genealógicos.La lectura del texto exige toda mi atención ya que hay muchos términos nuevos que no se relacionan con los conocimientos adquiridos y ponen a prueba mi comprensión lectora. El ADN nos ofrece nuevos enigmas que se relacionan con nuestro pasado, presente y futuro…¿tal vez?
Principales actualizaciones y mejoras en las Coincidencias de ADN de MyHeritage
Estamos encantados de anunciar las principales actualizaciones y mejoras de las funciones de Coincidencias de ADN lanzadas hoy para todos nuestros usuarios. Todo aquel que haya realizado una prueba de ADN MyHeritage, y que haya cargado datos de ADN de otra empresa, recibirá ahora coincidencias de ADN más precisas; mayor cantidad de coincidencias (aproximadamente 10 veces más); menos falsos positivos; estimaciones de parentesco más específicas y precisas; e indicaciones sobre las coincidencias de ADN de inferior fiabilidad para ayudar a centrar la investigación en ellas. También añadimos la característica Navegador de Cromosomas solicitada desde hace mucho tiempo, que se describe a continuación.
Estos avances han sido logrados por nuestro Equipo Científico a través de varios meses. Tomaron mucho tiempo y esfuerzo porque queríamos perfeccionar el trabajo científico y proporcionar a nuestros usuarios resultados óptimos.
¿Qué son las Coincidencias de ADN?
MyHeritage DNA actualmente tiene más de un millón de personas en la base de datos de ADN -1.075 millones, para ser exactos-. Las Coincidencias de ADN comparan los kits de ADN en la base de datos de MyHeritage entre sí, para encontrar familiares, es decir, individuos que comparten segmentos de ADN entre sí, y explicar cómo se relacionan estos individuos. La presencia de segmentos de ADN compartidos entre dos personas puede indicar una relación sanguínea, lo que significa que los segmentos compartidos fueron heredados de un antepasado común. Si los segmentos compartidos son numerosos y grandes, una relación de sangre es más segura. Por otra parte, si los segmentos compartidos son pequeños en número y tamaño, también puede ser una cuestión de coincidencia, lo que indica que no existe ninguna relación sanguínea. Cuando se reporta una coincidencia que no es un pariente en absoluto, es un falso positivo.
Si usted ha realizado una prueba de ADN MyHeritage y ha recibido los resultados, o ha cargado sus datos de ADN a MyHeritage, entonces habrá recibido una lista de sus coincidencias de ADN. Las coincidencias se actualizan diariamente, y los usuarios son notificados por correo electrónico semanalmente sobre las mejores nuevas coincidencias que recibieron esa semana. Por «mejores» nos referimos a las coincidencias que tienen la mayor cantidad de ADN compartido, lo que indica una relación cercana. La lista de coincidencias de ADN muestra los individuos que comparten segmentos de ADN con usted, la cantidad y porcentaje de ADN que comparten, el número de segmentos de ADN y el tamaño del segmento compartido más grande. MyHeritage también estima la relación analizando el número y tamaño de los segmentos de ADN compartidos en cada coincidencia y comparándolos con un grupo de referencia de cientos de miles de otras coincidencias con las vinculaciones conocidas según los árboles genealógicos que fueron confirmadas por ADN. La página de Análisis de Coincidencias de ADN ofrece pistas que usted puede seguir para rastrear su origen hasta su antepasado común.
A partir de hoy, los usuarios que hayan recibido anteriormente coincidencias de ADN, verán las coincidencias modificadas y mejoradas después de esta mejora. Esto significa que aparecerán muchas coincidencias nuevas. Algunas coincidencias que existían antes, que eran falsos positivos, desaparecerán. Muchas coincidencias tendrán sus parámetros cambiados (por ejemplo, la cantidad de ADN compartido) a valores más precisos. Los usuarios que aún no hayan obtenido ninguna coincidencia recibirán los resultados de mayor calidad desde el primer día.
¿Cómo funciona Coincidencias de ADN?

Representación esquemática de la cadena que produce coincidencias de ADN.
Empecemos con una breve descripción de cómo funciona las coincidencias de ADN. Luego profundizaremos en las mejoras que hemos hecho en las diferentes etapas del proceso.
El proceso comienza cuando usted toma una prueba de ADN y envía su muestra a nuestro laboratorio. En el laboratorio, leemos su ADN y elaboramos un archivo de datos con la información. No leemos cada parte de su ADN, que asciende a unos 3 mil millones de puntos. Este es un método costoso llamado secuenciación genómica completa, actualmente reservado para aplicaciones clínicas y específicas de investigación. En lugar de ello, nos enfocamos en leer aproximadamente 700.000 posiciones en su ADN que se sabe que varían entre individuos, llamados polimorfismos de nucleótidos simples (SNPs, pronunciados «snips»). Este método se llama genotipado y produce un archivo de datos que enumera cada SNP que leemos, su posición en su ADN y los dos genotipos que encontramos allí (es decir, el A, T, G o C que heredó de cada padre). Si ha cargado datos de ADN de otro servicio, recibimos el archivo de datos con la misma información.
A continuación, utilizamos la imputación para determinar los SNPs que no hemos leído. Considere la posibilidad de imputar el ADN como si leyera una frase con algunas de las letras faltantes – hay una gran probabilidad de que pueda deducir las letras perdidas del contexto. No todos los proveedores de servicios de ADN leen los mismos SNPs. Para encontrar coincidencias de ADN para individuos que usaron diferentes proveedores de servicios de ADN, es importante deducir los SNPs que no se leyeron antes de comparar los resultados. Algunas personas cuestionan la exactitud de la imputación. Sin embargo, encontramos que este método es muy preciso cuando se usa correctamente, y en algunas situaciones su uso es inevitable.
Después de la imputación viene el phasing. En cada par de cromosomas, cada persona recibe un cromosoma de su madre y uno de su padre. La tecnología de genotipado que lee su muestra de ADN determina qué genotipos heredó de sus padres para cada SNP, pero no nos dice qué grupos de variantes fueron co-heredados del mismo padre. El phasing nos ayuda a resolver esto. Agrupa todas las variantes heredadas de uno de tus padres en un contenedor y las variantes heredadas del otro padre en otro contenedor.
El siguiente paso es realizar la comparación real y comparar entre sí todos los kits de ADN de la base de datos que no hayan sido eliminados por sus propietarios. Hacemos esto en un sistema muy escalable llamado Hadoop que nos permite realizar un procesamiento distribuido masivo de manera muy eficiente. El emparejamiento identifica los segmentos compartidos entre cada par de kits, de los cuales se puede deducir la relación de los dos individuos (si hay alguno). Los segmentos compartidos adyacentes son luego «cosidos» si se consideran contiguos.
Finalmente, utilizamos algoritmos de estadística avanzada llamados clasificadores para revisar las coincidencias de ADN y rechazar falsos positivos, determinar el nivel de confiabilidad de las coincidencias que no fueron rechazadas y sugerir el tipo de relación para cada coincidencia. Así es como creamos tu lista de coincidencias de ADN.
¿Qué hemos mejorado en las Coincidencias de ADN?
Hemos mejorado significativamente la precisión de nuestra imputación al multiplicar por más de diez el número de genomas de referencia. Así como leer 10 veces más libros le permitiría a una persona inferir con precisión letras faltantes de más frases, incrementando nuestro panel genómico de referencia en gran medida aumentó nuestra habilidad para imputar SNPs que no leímos con mas precisión.
Hemos arreglado el phasing. El procesamiento previo de Coincidencias de ADN tenía errores ocasionales en la fase de phasing. Estos errores causaron algunos falsos positivos donde anteriormente sobreestimamos segmentos compartidos de parientes muy lejanos. También causó problemas donde antes se subestimaba los segmentos compartidos de parientes cercanos. Ahora utilizamos un algoritmo mejor que corrige estos errores de phasing.
En la fase de Coincidencia hemos recalibrado el umbral para los errores de genotipado. La tecnología que lee su muestra de ADN ocasionalmente comete errores. Éstos se denominan errores de genotipado. Si se produce un error de genotipado en medio de lo que debería ser un segmento compartido entre las coincidencias de ADN, ese segmento no parecerá idéntico y puede dividirse en dos segmentos coincidentes más pequeños. Hemos recalibrado el umbral para cuando ignoramos pequeños desajustes entre segmentos coincidentes, y en su lugar tratamos los segmentos compartidos como idénticos a pesar de las piezas pequeñas que no coinciden. Este método compensa errores inevitables de genotipado. Si ignoramos secciones desajustadas que son demasiado grandes, asumiremos accidentalmente que un segmento se comparte cuando realmente no lo es; si no ignoramos secciones desajustadas que son el resultado de errores de genotipado, es probable que perdamos coincidencias reales de ADN. La nueva calibración es más estricta que la anterior, lo que significa que se producirán menos falsos positivos.
Ahora se admiten coincidencias más lejanas. Después de aumentar la precisión de las coincidencias y calibrar los parámetros anteriores, nos sentimos a la altura de poder presentarle coincidencias más distantes. Anteriormente, el mínimo de ADN compartido para una coincidencia era de 12 cM y ahora el mínimo es de 8 cM. Esto, junto con las otras mejoras produjeron un aumento diez veces mayor en el número de coincidencias de ADN que nuestros usuarios recibirán ahora.
Estas coincidencias aparecerán automáticamente para cualquiera que ya haya realizado una prueba de ADN de MyHeritage o cualquiera que haya cargado su ADN en MyHeritage en el pasado y para cualquiera que lo haga en el futuro.
El último paso de DNA Matching es filtrar falsos positivos y estimar la relación específica entre dos individuos con segmentos de ADN compartidos. Debido a que muchos de nosotros somos descendientes de los mismos antepasados muy antiguos, a menudo tenemos pequeños segmentos de ADN compartidos con individuos que realmente no consideraríamos familia. Buscamos un método para filtrar tales coincidencias que sólo frustran a los genealogistas. Para este fin, medimos falsos positivos internamente observando tríos – estos son conjuntos de niño, madre y padre que fueron probados con los kits de ADN MyHeritage, y recibieron resultados que validaron que las relaciones entre los padres y el niño son correctas. Cualquier coincidencia que un niño tenga con otro individuo, que no coincida ni con el padre ni con la madre, se sospecha que es un falso positivo y se le llama coincidencia de sólo un niño. Medimos el porcentaje de coincidencias sólo para niños entre todas las coincidencias que se devuelven para niños en todos los tríos conocidos de MyHeritage, y esta cifra se denomina porcentaje de falsos positivos sospechosos indicados por coincidencias sólo para niños. Conseguimos reducir esta cifra al 16-20 por ciento, lo que es un buen resultado que hasta donde sabemos es equivalente o mejor que todos los demás servicios de ADN. Nuestros algoritmos de clasificación mejorados han tenido éxito en llevar nuestra tasa de falsos positivos a un mínimo histórico.
Pero no nos detuvimos allí. Queríamos crear un método que le permitiera enfocar sus búsquedas genealógicas de manera más efectiva. Para ello, utilizamos nuestros algoritmos estadísticos para clasificar las coincidencias en: alta, media y baja confianza. Las coincidencias que son de baja o mediana confianza se etiquetan como tales en el sitio web. Son coincidencias de ADN que deben tratarse con escepticismo porque corren el riesgo de ser falsos positivos. Tales coincidencias suelen tener muy pocos segmentos de ADN compartidos, muy pequeños. Estas indicaciones le permiten aprovechar al máximo su tiempo. Primero haga un seguimiento de los resultados de las coincidencias de mayor confianza, y si está de humor para un desafío, examine los resultados de las coincidencias de menor y media confianza para encontrar tesoros ocultos. Tenga en cuenta que los resultados de fiabilidad baja y media se excluyen de los correos electrónicos semanales de notificación de nuevos partidos.
Los nuevos sistemas de clasificación son tan buenos que el porcentaje de coincidencias sólo para niños que no se señalan como de confianza baja o media es ahora inferior al 5%. En otras palabras, cada vez que usted revisa una coincidencia de ADN en MyHeritage que no está marcada como baja confianza o confianza media, ahora puede estar casi seguro de que no está perdiendo su tiempo en un falso positivo. Si la coincidencia que está revisando se estima que es un primo segundo o más cercano, hay tanto ADN compartido que puede estar seguro de que no es un falso positivo.
La precisión de estimar una relación de una Coincidencia de ADN se mide utilizando dos parámetros llamados recuperación y precisión. La precisión perfecta significa tanto decirle a un usuario la relación correcta con una coincidencia de ADN en cada ocasión (recall), como sugerir sólo esa relación y no proponer una gama más amplia de posibles relaciones (precisión). Por ejemplo, si dos individuos son de hecho hermanos, un algoritmo perfecto sugerirá que son hermanos y sólo sugieren que son hermanos; no estimará que sean hermanos o primos. (Sin embargo, biológicamente, debido a la naturaleza de la herencia del ADN, este algoritmo teóricamente perfecto no es posible). MyHeritage ahora puede sugerir la relación correcta de las coincidencias de ADN el 93% del tiempo para los parientes lejanos como el 4to y 5to primos que es increíblemente difícil de hacer. Para los parientes más cercanos, la precisión es mucho mayor y cercana al 100%. Al mismo tiempo, sólo sugeriremos 2 o 3 posibles relaciones para las coincidencias de ADN que son primos o parientes más cercanos. Para los primos lejanos mostraremos un promedio de hasta 5 posibles relaciones (tales como primo segundo una vez removido y primo tercero) – un rango relativamente estrecho, considerando lo anterior. La precisión y el recuerdo de las estimaciones de la relación de MyHeritage son ahora mucho mejores que antes.
Validamos la alta calidad de nuestro nuevo algoritmo DNA Matching comparando las nuevas listas de coincidencias de ADN con las producidas por otras compañías de ADN y los resultados son muy similares.
Ciertas poblaciones particularmente endogámicas, como los judíos ashkenazis, plantean un desafío único de concordancia de ADN. Debido a que estas poblaciones experimentaron matrimonios mixtos significativos, los individuos no relacionados genéticamente dentro de esta población tienen un ADN más compartido de lo que se esperaría para los no familiares. MyHeritage preparó un algoritmo clasificador adicional utilizando el aprendizaje automático para clasificar las relaciones Ashkenazi con mayor resolución que cualquier otro servicio de ADN. Usamos este clasificador para proporcionar un mejor rechazo de los falsos positivos para los judíos ashkenazis, llevándolos al mismo nivel de falsos positivos que la población general.
¿Qué significan estas mejoras para los usuarios de MyHeritage ADN?
Ahora, conseguirá:
Más precisión en las Coincidencias de ADN
Alrededor de 10 veces más Coincidencias de ADN
Estimaciones de parentesco más específicas y precisas
Indicaciones de Coincidencias de ADN con Niveles de Confianza para ayudar a centrar sus esfuerzos de investigación
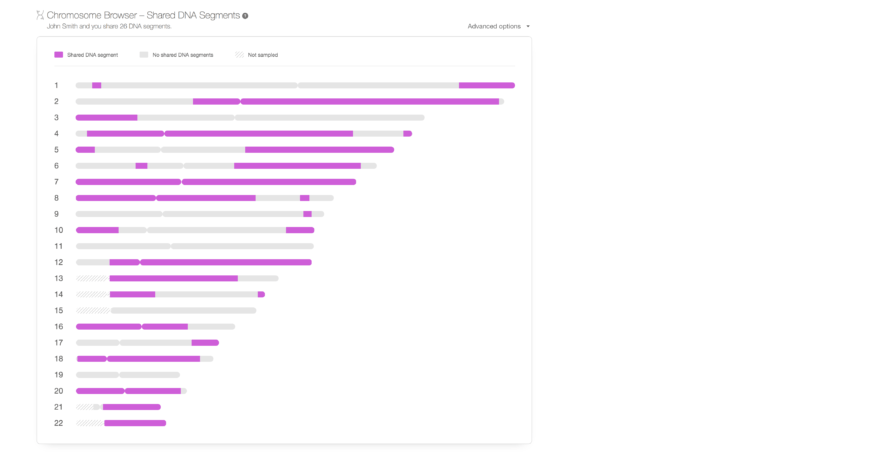
Navegador de Cromosomas
Junto con las mejoras en la precisión, también hemos añadido nuevas funciones para mejorar el uso de las coincidencias de ADN. El primero, por demanda popular, es un navegador de cromosomas para compartir coincidencias de ADN. Se agregó a la página Análisis de Coincidencias de ADN.

Un navegador de cromosomas es una representación esquemática de los cromosomas de una persona donde se pueden visualizar los segmentos de ADN. Muchos de nuestros usuarios han solicitado un navegador cromosómico y nosotros sabemos que es una herramienta importante para los genealogistas. Por lo tanto, prometimos que desarrollaríamos uno y ahora hemos cumplido con esta promesa. El nuevo Navegador de cromosomas de MyHeritage es una versión inicial, que se ampliará en breve, destinada a visualizar segmentos de ADN compartidos para cualquier coincidencia de ADN. Es una función gratuita que pueden utilizar todos los usuarios de MyHeritage que hayan realizado la prueba de ADN o cargado sus datos de ADN. Muestra los segmentos compartidos entre usted y una coincidencia de ADN en color púrpura. Al pasar el ratón por encima de cualquier segmento compartido se puede ver la posición genómica del segmento compartido, el tamaño del segmento y el número de SNPs allí. Los segmentos grises no son compartidos con el ADN coincidente y las secciones cruzadas no fueron analizadas debido a la falta de SNPs en esas áreas. Tenga en cuenta que aunque nunca permitiremos que otro usuario descargue sus datos de ADN sin procesar, si otro usuario tiene un segmento compartido con usted y puede ver los detalles (posición y tamaño) y luego revisando la información de ese segmento en su propio ADN, ese otro usuario puede deducir los genotipos que usted tiene en su ADN en ese segmento en particular. Los usuarios que prefieran evitar que otros usuarios que coincidan con su ADN vean los detalles de segmentos compartidos pueden optar por no utilizar esta función utilizando una nueva configuración de privacidad que hemos añadido con este fin.
El navegador de cromosomas también incluye la capacidad de descargar datos sobre segmentos compartidos. Esto es accesible a través del menú «Opciones Avanzadas» en la esquina superior derecha del Navegador de Cromosomas. Los usuarios avanzados pueden utilizar esta opción para descargar la información sobre los segmentos compartidos y luego utilizarla para visualizarla en otras herramientas o navegadores cromosómicos. Más características aparecerán pronto, como la posibilidad de ver tres o más segmentos compartidos del ADN coincidente en el Navegador de Cromosomas simultáneamente. Ver los segmentos compartidos de múltiples coincidencias de ADN al mismo tiempo le ayuda a rastrear e identificar al antepasado compartido que transmitió el segmento a todas las coincidencias de ADN que lo comparten y, a continuación, descubrir cómo están relacionados. También estamos planeando la posibilidad de añadir pronto la opción de imprimir los segmentos compartidos mostrados por el Navegador de Cromosomas.
Con algo de práctica, estamos seguros de que nuestros usuarios podrán utilizar la nueva función del Navegador de Cromosomas para empezar a identificar segmentos específicos en su ADN y del antepasado del que se originaron, obtener una mejor comprensión de sus coincidencias de ADN, y también saber cuál es la relación que conecta estas coincidencias de ADN. Esperamos que esto ayude a nuestra comunidad a romper las murallas de ladrillo, rastrear sus antepasados y entender cómo se vinculan con los familiares descubiertos a través de las coincidencias de ADN.
Lavado de cara y navegación más fácil
Como parte de esta actualización, realizamos pequeñas revisiones a la interfaz de usuario de las Coincidencias de ADN para una mejor coherencia con las otras pantallas de ADN. La mayoría de estos cambios son pequeños y apenas perceptibles, como los botones en la lista de coincidencias de ADN que son morados en lugar de naranja. Sin embargo, una mejora importante es que la página de la Lista de Coincidencias de ADN aúna los detalles del kit de ADN que está viendo arriba, por lo que al desplazarse hacia abajo a través de la lista no perderá nunca de vista qué coincidencias está viendo.

Trabajos en curso
Nuestro trabajo no está completo. La coincidencia de los datos de ADN es siempre un trabajo en progreso y será mejorado constantemente por nuestra parte en lo futuro. El creciente tamaño de nuestra base de datos de ADN, así como el aumento de la asociación entre los kits de ADN y los árboles genealógicos, nos proporcionan más oportunidades para optimizar los algoritmos de comparación de ADN, y nos proponemos hacerlo con regularidad y mejorar aún más la precisión.
Con respecto a los datos de ADN cargados desde otros servicios, todavía no ofrecemos soporte para la coincidencia de ADN con los kits de ADN basados en el chip GSA de Illumina. Entre ellos se incluyen kits de 23andMe (versión V5 reciente) y Living DNA. Tenemos soporte para los datos de ADN de los chips GSA que operan en nuestro laboratorio; está funcionando bastante bien, pero todavía no es perfecto, así que decidimos excluirlo de este lanzamiento hasta que se perfeccione. Esto se añadirá en los próximos meses.
Las estimaciones de etnicidad están separadas de la coincidencias de ADN y las mejoras descritas aquí no afectan a las estimaciones de etnicidad. Estamos planeando una actualización de nuestros informes de etnicidad en los próximos meses para mejorar su precisión también. ¡Siga atento!
Próximos pasos
Si aún no lo ha hecho, solicite un kit de ADN MyHeritage para beneficiarse de estas nuevas características y mejoras. Si ya se ha realizado la prueba usted mismo, considere la posibilidad de obtener kits de ADN para algunos de sus familiares, especialmente los mayores, para encontrar más parientes y triangular sus propias coincidencias. Por ejemplo al examinar a un primo de su madre o padre, cualquier coincidencia con parientes nuevos que usted ya tenga y que también sean compartidos con ese primo, puede ser triangulada con un antepasado común, a través de un recorrido hacia un antepasado más reciente en su árbol genealógico que comparte con ese primo. El nuevo Navegador de Cromosomas será útil para comprender esas coincidencias. Por lo tanto, si hay una rama en particular en su árbol genealógico que le interesa explorar más a fondo, compre kits de ADN adicionales para los parientes mayores en esa rama.
Si ha realizado una prueba de ADN anteriormente en alguna empresa diferente, cargue sus datos de ADN en MyHeritage. MyHeritage es de los tres servicios de ADN más grandes el único que ofrece soporte para la subida de datos de ADN. Aproveche esto mientras todavía es gratuito y obtenga coincidencias de ADN y estimaciones de etnicidad gratuitas para sus datos actuales. Con la considerable base de datos de ADN de MyHeritage de más de un millón de personas, la mayoría de las cuales solamente se realizaron pruebas en MyHeritage, hacer esto es muy sencillo. Obtendrá sus resultados gratis en uno o dos días o incluso antes.
Si ya maneja más de un kit de ADN en MyHeritage, por favor tómese el tiempo para verificar que cada kit que maneja está asociado con la persona adecuada. Esto se puede arreglar, si es necesario, utilizando la página «Administrar kits de ADN», accesible desde el menú ADN. Utilice la opción «Reasignar kit a otra persona» si tiene un kit que no está asociado correctamente. Esto es necesario si todos los kits que subió para varios familiares siguen asociados con el perfil de su propio árbol genealógico.
Finalmente, los kits de ADN en MyHeritage son mucho más provechosos cuando hay un árbol genealógico asociado con ellos. Esto le permite obtener una mejor comprensión de sus Coincidencias de ADN, por ejemplo, mediante la detección de Smart Matches, apellidos ancestrales compartidos o lugares de nacimiento comunes entre usted y cualquier Coincidencia de ADN. Si usted tiene un kit de ADN en MyHeritage, pero no tiene un árbol genealógico o tiene un árbol familiar muy pequeño, ahora es un buen momento para crear un árbol genealógico o mejorar el que tiene. Esto beneficiará a sus coincidencias de ADN, pero principalmente, le beneficiará a usted.
Disfrútelo,
El equipo de MyHeritage
Analia
enero 29, 2018
Es de suma importancia poder descargar el listado de las coincidencias del ADN, y un filtrado de Nuevas coincidencias,ya que no lo tiene.